Не учи агентов без фундамента: путь от API до production
Каждую неделю выходит новый фреймворк для AI-агентов, и каждый раз разработчики бросаются его осваивать. LangChain, LangGraph, MCP, AutoGPT, CrewAI — список растёт быстрее, чем успеваешь запомнить. Но за этой гонкой за новинками скрывается неприятная правда: большинство агентных проектов падают в production именно потому, что их авторы пропустили фундамент. Не потому что фреймворк плохой, не потому что модель слабая — а потому что никто не объяснил, как работают контекстные окна, эмбеддинги и семантический поиск.
В этом посте мы пройдём путь, который предлагают лучшие образовательные программы: от простого API-вызова к полноценному агенту через единый проект. Без сухой теории — с конкретными числами, реальными ограничениями и объяснением, почему каждый слой необходим.
Почему агенты — это финиш, а не старт
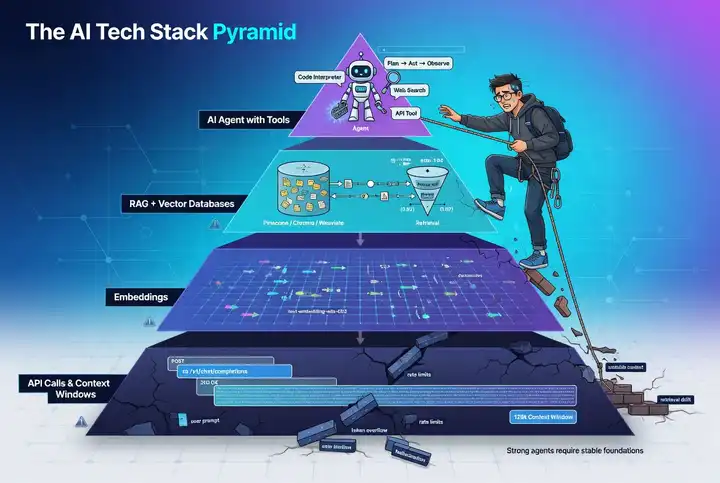
Агент — это не просто LLM, которая отвечает на вопросы. Это автономная система с памятью, инструментами и способностью самостоятельно принимать решения. Но автономия требует фундамента. Представьте, что вы строите десятиэтажный дом, начиная с крыши. Технически возможно — но ветер снесёт его при первом же порыве.
С агентами то же самое. Если вы не понимаете, как работает контекстное окно, вы не поймёте, почему агент забывает важные детали в середине длинного диалога. Если не знаете, что такое эмбеддинги, не сможете построить систему, которая находит релевантные документы. Если пропустите RAG, агент будет галлюцинировать на каждом втором запросе. Агент без фундамента — это дорогой чат-бот, который врёт убедительно.
Контекстное окно: память, которой всегда не хватает
Когда вы задаёте вопрос языковой модели, она не «понимает» его в человеческом смысле. Она обрабатывает последовательность токенов — примерно три четверти английского слова каждый — и предсказывает следующий. Всё, что модель «помнит» во время одного разговора, хранится в контекстном окне.
Размеры этих окон растут: xAI Grok 4 предлагает 256 тысяч токенов, Claude 3 Opus — 200 тысяч, Gemini 2.5 Pro — целый миллион. Цифры впечатляют, но они обманчивы. Даже в моделях с миллионным окном информация в середине длинного документа обрабатывается хуже, чем в начале или конце. Это не баг — это архитектурное ограничение трансформеров.
Представьте корпоративную базу знаний объёмом 500 гигабайт. Даже миллион токенов — это примерно 50 типовых бизнес-документов. Остальные 499+ гигабайт остаются за бортом. Контекстное окно — это оперативная память, а не жёсткий диск. И если вы не понимаете этого ограничения, вы не сможете спроектировать систему, которая работает с реальными объёмами данных.
Вот ещё один нюанс, который редко объясняют. Дайте модели задачу с лишним контекстом: «У Sally 14 яблок, яблоки часто красные, 12 — хорошее число, у Bob два зелёных яблока, зелёные часто невкусные. Сколько яблок у них всего?» Модель должна ответить 16, но ей приходится отсеивать нерелевантную информацию о цвете и вкусе. Чем больше мусора в контексте, тем выше вероятность ошибки. Это называется проблемой внимания — и она критична для агентов, которые собирают контекст из множества источников.
Эмбеддинги: когда смысл превращается в математику
Если контекстное окно не может вместить все данные, нужен способ находить релевантные фрагменты. Здесь на сцену выходят эмбеддинги — векторные представления текста.
Специальная модель превращает фразу в массив чисел фиксированной длины, обычно 1536 измерений. Каждое измерение отвечает за какой-то семантический аспект: формальность, тематику, эмоциональную окраску. Магия в том, что похожие по смыслу тексты получают близкие векторы. «Отпуск» и «каникулы» окажутся математически ближе друг к другу, чем «отпуск» и «налоговая декларация».
Для бизнеса это означает революцию в поиске. Сотрудник спрашивает: «Можно ли носить джинсы на работу?» Система находит дресс-код, даже если в нём нет слова «джинсы». Потому что эмбеддинги понимают, что «джинсы» семантически близки к «повседневная одежда» и «неформальный стиль». Без эмбеддингов поиск работает как Ctrl+F — с ними он работает как человеческое понимание.
RAG: как научить модель читать то, чего она не видела
RAG, или Retrieval-Augmented Generation, решает центральную проблему LLM: их знания ограничены датой обучения и не включают приватные данные компании. Если спросить стандартную модель о внутренней политике вашей организации, она выдумает убедительный, но ложный ответ.
RAG работает в три этапа. Сначала запрос пользователя превращается в эмбеддинг. Затем система ищет в векторной базе наиболее похожие документы. Наконец, эти документы подставляются в промпт вместе с исходным вопросом, и модель генерирует ответ, опираясь на предоставленный контекст. Результат: ответы точные, проверяемые и привязанные к реальным документам.
Но RAG — не волшебная палочка. Качество зависит от того, как документы разбиты на фрагменты. Если фрагменты слишком мелкие — теряется контекст. Если слишком крупные — в контекстное окно помещается мало документов. Для юридических текстов используют paragraph-based chunking с умными перекрытиями, для технической документации — разбиение по заголовкам. Выбор стратегии chunking напрямую влияет на качество ответов — и это решение принимает разработчик, не модель.
LangChain: абстракция, которая экономит 70% кода
Когда вы начинаете строить AI-приложение, быстро обнаруживаете, что каждый провайдер LLM имеет свой SDK, свой формат запросов, свою систему ошибок. Переключение с OpenAI на Anthropic требует переписывания кода. LangChain решает эту проблему, предоставляя единый интерфейс.
Но LangChain — это не просто обёртка. Он предоставляет готовые компоненты: загрузка документов, разбиение текста, вычисление эмбеддингов, поиск в векторных базах, управление памятью разговора. Вместо сотен строк кода для подключения к Pinecone — один метод. Вместо ручного формирования промптов — шаблоны с переменными.
Реальные проекты показывают сокращение объёма кода на 70% при использовании LangChain по сравнению с прямым использованием SDK провайдеров. Но есть и обратная сторона: абстракция скрывает детали, и когда что-то идёт не так — например, модель возвращает неожиданный формат — отладка усложняется. Опытные разработчики начинают с LangChain для прототипирования, а в production переходят на собственные реализации критических компонентов.
LangGraph: когда линейного пайплайна недостаточно
Простые RAG-системы работают линейно: запрос → поиск → генерация ответа. Но реальные задачи редко бывают линейными. Представьте проверку документа на соответствие GDPR: нужно найти политики конфиденциальности, извлечь ключевые положения, сравнить с законом, выявить несоответствия, сгенерировать рекомендации. Это многошаговый процесс с ветвлениями и циклами.
LangGraph расширяет LangChain, позволяя строить графы состояний. Каждый узел отвечает за конкретную задачу: поиск документов, извлечение информации, анализ соответствия. Рёбра определяют переходы на основе условий. Если узел анализа выявляет низкий уровень соответствия, условное ребро возвращает выполнение к узлу поиска дополнительных документов. Если высокий — направляет к генерации отчёта.
Важное отличие от обычного кода: состояние явно определено и передаётся между узлами. Это делает систему предсказуемой и тестируемой. Вы можете остановить выполнение на любом шаге, проверить состояние, внести изменения и продолжить. То, что в обычном коде требует сложной отладки, в LangGraph работает из коробки.
MCP: универсальный порт для агентов
Model Context Protocol, представленный Anthropic в ноябре 2024, решает проблему интеграции агентов с внешними системами. Раньше для каждой интеграции — базы данных, GitHub, CRM — приходилось писать отдельный адаптер. MCP заменяет это на единый протокол, похожий на USB для AI.
MCP-сервер объявляет доступные инструменты с их параметрами и типами возвращаемых значений. Когда агент сталкивается с запросом, который требует доступа к внешней системе — например, «какой статус у заказа 12345?» — он сам решает, какой инструмент вызвать, формирует правильные параметры и обрабатывает ответ. Разработчику не нужно вручную прописывать логику вызова API.
Ключевое преимущество — экосистема. Сообщество создаёт MCP-серверы для популярных инструментов: GitHub, SQL-базы, Slack, Notion. Вы подключаете готовый сервер к своему агенту, и он сразу получает доступ к функциональности. Это меняет экономику разработки: вместо написания интеграций с нуля вы комбинируете готовые компоненты, как LEGO.
Промпт-инжиниринг: навык, который связывает всё воедино
Несмотря на всю технологическую сложность, промпт-инжиниринг остаётся фундаментальным навыком. Качество промпта напрямую влияет на качество ответа — независимо от того, используете ли вы простой RAG или многоузловой граф LangGraph.
Современный промпт-инжиниринг вышел за рамки трюков вроде «think step by step». Сегодня это проектирование системных инструкций, которые определяют роль модели, ограничения, формат вывода. Zero-shot prompting — запрос без примеров — работает для простых задач. One-shot и few-shot prompting показывают модели примеры желаемого поведения, что особенно эффективно для структурированных форматов. Chain-of-thought заставляет модель рассуждать вслух перед ответом, повышая точность на сложных задачах.
Важный принцип: промпт — это не статический текст, а динамический шаблон. Он комбинирует системную инструкцию, контекст из RAG, историю разговора и текущий запрос. Каждый компонент вносит свой вклад в финальный результат. Плохой промпт может испортить даже идеально настроенный стек.
Часто задаваемые вопросы
Можно ли сразу начать с LangGraph, пропустив LangChain?
Технически да, но практически нет. LangGraph строится на абстракциях LangChain, и без понимания базовых компонентов — моделей, эмбеддингов, памяти — вы будете копировать код, не понимая, что он делает. Это верный путь к системе, которая падает при первой нестандартной ситуации.
Нужна ли векторная база для небольших проектов?
Для нескольких сотен документов можно обойтись эмбеддингами в памяти или даже полнотекстовым поиском. Но как только масштаб превышает тысячи документов, векторная база становится необходимостью. Выбор конкретной базы — Pinecone, Chroma, Weaviate — зависит от инфраструктуры и требований к скорости.
В чём реальная разница между агентом и чат-ботом?
Чат-бот отвечает на вопросы на основе заданной логики или найденного контекста. Агент самостоятельно определяет последовательность действий для достижения цели, использует инструменты и адаптируется к ситуации. Чат-бот — интерфейс, агент — автономная система, которая действует во внешнем мире. Но автономия возможна только при условии, что вы понимаете все слои под ней.
Итог
Современный AI-стек — это сложная экосистема взаимосвязанных компонентов. LLM обеспечивают языковое понимание, эмбеддинги превращают смысл в математику, векторные базы делают поиск масштабируемым, RAG подключает модели к реальным данным, LangChain абстрагирует провайдеров, LangGraph оркестрирует сложные процессы, MCP стандартизирует интеграции. Агент — это вершина пирамиды, а не её фундамент.
Если вы пропустите хотя бы один слой, система будет работать на демо и падать в production. Не гонитесь за последними фреймворками, пока не разберётесь в базе. Потратьте время на фундамент — и ваши агенты будут не впечатлять на презентациях, а работать в реальном бизнесе.