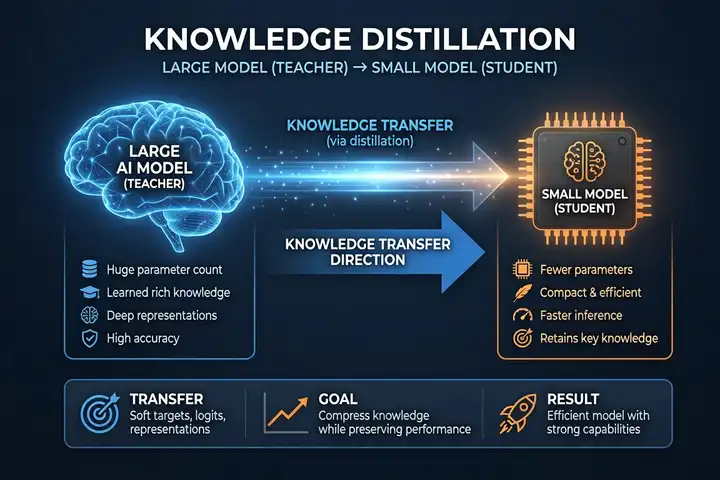
ZOPP: как заставить маленькую модель учиться у большой без потери качества
Когда DeepSeek показал, что RL-посттренинг превращает языковую модель в reasoning-машину, все обрадовались. Но есть нюанс: эти результаты получены на моделях с десятками миллиардов параметров, работающих на A100/H100 в дата-центре. Попробуйте взять ту же технику и применить к модели для мобильного телефона, AR-очков или робота — и получите ноль. Группа исследователей из команды Qwen предложила решение: ZOPP (Zone of Proximal Policy Optimization) — метод, который переносит знания большого учителя в маленького ученика через промпт, а не через градиент. Результат: модель 0.8B с ZOPP догоняет по качеству 9B без дистилляции.
Проблема: почему дистилляция ломается на маленьких моделях
Классическая дистилляция знаний работает на интуитивном уровне: учитель генерирует ответ, ученик учится повторять его распределение вероятностей (логиты). На бумаге — элегантно и теоретически обосновано. На практике для маленького ученика это катастрофа. Исследования 2025–2026 годов показывают, что разница в размере между учителем и учеником в 10–30 раз приводит к хрупкости: ученик начинает заучивать конкретные ответы вместо понимания паттернов, а распределение логитов учителя не соответствует зоне компетенций маленькой модели.
Вторая проблема — RL-посттренинг. Когда вы берёте ответ учителя и вставляете его в политический градиент как будто это ответ ученика — вы нарушаете основное допущение PPO (Proximal Policy Optimization): данные должны быть on-policy, то есть сгенерированы текущей версией модели. Учитель генерирует off-policy, а градиент считается так, будто данные пришли от ученика. Результат — дрифт, накопление ошибок и отсутствие улучшений на сложных вопросах. DeepSeekMath показал, что GRPO (Group Relative Policy Optimization) частично решает эту проблему для больших моделей, но маленькие всё равно проваливаются.
Существующие гибридные подходы (RL + дистилляция) пытаются чинить дрифт через auxiliary distillation term, но это создаёт новый: обратный дрифт от смешивания каналов обучения. Два потока градиента — от RL и от дистилляции — конфликтуют, и в маленькой модели ни один не побеждает.
ZOPP: учитель в промпте, градиент — на своих ответах
ZOPP берёт за основу GRPO из DeepSeekMath и переформулирует две ключевых проблемы — BCQ (Best Candidate Question) и NCQ (Negative Candidate Question). Главная идея: перенести учителя из градиента в промпт.
BCQ: правильный ответ + неправильный
Для сложного вопроса берём правильный ответ учителя и подмешиваем к нему неправильный ответ самого ученика. Формулируем промпт типа: «Вот вопрос, вот правильный ответ (от учителя), вот неправильный ответ (от тебя). Объясни, какой правильный и почему».
Что происходит: ученик остаётся в своей зоне компетенций — он сравнивает варианты, а не генерирует с нуля. При этом градиент считается на ответе ученика, а не учителя. Это принципиально отличается от стандартной дистилляции: ученик учится на своих ошибках, а не на копировании учителя.
BCQ работает по аналогии с методами из domain randomization и контрастным обучением: модель получает сигнал через различие, а не через прямое подражание.
NCQ: собственный негативный опыт
NCQ (Negative Candidate Question) — для вопросов, где учитель тоже не справляется. В этом случае у нас нет «правильного» ответа для BCQ-пары. Решение: собираем собственные неправильные rollout ученика в единый промпт и просим его найти паттерн в собственных ошибках. Формулировка: «Вот три твоих неправильных ответа на этот тип вопросов. Что в них общего? Где ты ошибаешься?»
Это усиливает обучение на сложных случаях, где ни учитель, ни ученик не знают ответа. Ученик учится распознавать собственные режимы отказа — и избегать их.
Буфер промпт-реплея
Третий элемент — буфер промпт-реплея (prompt replay buffer). Запуски, где ученик ошибся, но учитель прав, сохраняются и циклически возвращаются в пул обучения. Это классический replay buffer из off-policy RL, адаптированный для промпт-реплея.
Эффект: ученик не забывает сложные вопросы между итерациями и остаётся в зоне ближайшего развития (по Выготскому) — не слишком легко, не безнадёжно сложно. Практически это означает, что на каждый вопрос из зоны учителя ученик получает несколько попыток с разными вариациями, прежде чем перейти к следующему.
Числа: от 0.8B до 9B
Эксперименты ставили на семействе Qwen3.5 VLM: четыре ученика (0.8B, 2B, 4B, 9B параметров) и один учитель (27B). Все модели обучались на датасете ZOPP-77K multimodal RL dataset, едином для всех масштабов. Это важно: обычно сравнения между масштабами проводят на разных данных, что делает их несопоставимыми.
Результаты измеряли через cumulative graduate count — долю вопросов, на которых ученик «догоняет» учителя (achieves equivalent or better performance). Метрика отражает именно способность ученика достичь учительского уровня на множестве вопросов, а не просто улучшение относительно baseline.
График на Figure 4 в статье показывает: для 2B модели ZOPP с BCQ + NCQ + replay buffer значительно превосходит vanilla GRPO по доле «выпусканных» вопросов. GRPO на 2B быстро насыщается — после 10K запусков прирост прекращается. ZOPP продолжает расти, потому что буфер промпт-реплея возвращает сложные вопросы через несколько итераций.
Ключевой результат: модель 0.8B с ZOPP достигает результатов, сопоставимых с 9B без дистилляции, при этом обучаясь на собственных rollout, а не на логитах учителя. Это означает, что frontier-качество теперь возможно на устройствах с ограниченным бюджетом памяти и вычислений.
Архитектурные детали: почему это работает
ZOPP модифицирует стандартный GRPO в двух местах. Во-первых, генерация rollout: вместо чистого rollout ученика на вопросе Q, промпт дополняется BCQ/NCQ-контекстом. Во-вторых, reward computation: награда за вопрос вычисляется не по единственному ответу, а по структурированному сравнению вариантов.
Конкретно: для BCQ reward считается как взвешенная сумма — правильный ответ учителя получает положительный reward, неправильный ответ ученика — отрицательный. Для NCQ reward вычисляется по паттерну ошибок в собственных rollout ученика. Это создаёт более информативный градиент, чем binary reward за правильный/неправильный ответ.
Full training step описан как Algorithm 1 в Appendix C статьи. Детали реализации: backbone — Qwen3.5 VLM, optimizer — AdamW, learning rate 1e-5 для учеников всех размеров, batch size 64, temperature 0.7 для генерации. Все ученики обучались на одном и том же 77K датасете — это важно для чистоты сравнения между масштабами.
Сравнение с альтернативами
Таблица 3 в статье сравнивает ZOPP с несколькими baselines на разных масштабах учеников. GRPO baseline (без дистилляции) показывает насыщение на 0.8B — модель быстро перестаёт улучшаться. Vanilla distillation (logit matching) работает лучше на больших учениках (4B, 9B), но на 0.8B и 2B проигрывает ZOPP. Hybrid RL+KD (auxiliary distillation term) занимает промежуточное положение, но не дотягивает до ZOPP ни на одном масштабе.
Главное преимущество ZOPP перед hybrid-подходами: отсутствие конфликтующих градиентов. Когда у вас два потока обучения (RL + distillation), они конкурируют за параметры модели. На маленькой модели это критично — у неё меньше «свободных» параметров, которые могут специализироваться под разные задачи. ZOPP убирает один поток полностью, оставляя только RL на собственных rollout.
Почему это важно для Edge AI
Вычислительный бюджет на мобильных устройствах, AR/VR-гарнитурах и роботах — на порядки меньше, чем в дата-центре. Frontier-достижения (reasoning, chain-of-thought, многошаговое планирование) остаются недоступны. ZOPP показывает, что знания большой модели можно «перелить» в маленькую без катастрофического дрифта — при условии, что передача идёт через промпт, а не через градиент.
Практический эффект: RL-посттренинг, который сейчас работает только на A100/H100, становится применим к моделям, работающим на Edge-устройствах. Это открывает путь к персонализированным агентам на смартфоне — с многошаговым планированием, памятью и адаптацией под пользователя.
Примеры применения: робот-помощник с 0.8B моделью на борту (Jetson Orin) может обучаться на данных от 27B учителя в облаке, а затем работать полностью автономно. AR-очки с персонализированным ИИ-ассистентом, который адаптируется к жестам и контексту пользователя за счёт reasoning-способностей, перенесённых через ZOPP. Медицинский ИИ на носимом устройстве, который рассуждает о показателях здоровья так же качественно, как cloud-модель.
Ограничения: зона учителя как потолок
ZOPP не решает фундаментальную проблему: если учитель не знает ответа, BCQ не работает. Зона обучения ограничена множеством вопросов, где учитель справляется. За пределами этой зоны — только NCQ, чей вклад скромнее (таблица 3 в статье).
На верхнем конце диапазона учеников (9B) вклад BCQ снижается — ученик и так справляется с большинством вопросов, и зона схлопывается в NCQ-only режим. Это не баг, а естественное следствие: чем компетентнее ученик, тем меньше «пространства для роста» в зоне учителя.
Авторы называют три направления для расширения зоны: синтетические промпты от экспертов (curated synthetic prompts), ансамбли учителей (ensembles of teachers) и curriculum-aware селекция вопросов. Но это будущая работа.
Часто задаваемые вопросы
Почему бы просто не обучать маленькую модель на данных учителя?
Классическая дистилляция учит ученика копировать логиты учителя. Это работает для больших разниц в размере, но создаёт brittle знания — ученик запоминает ответы, а не паттерны. ZOPP учит ученика рассуждать о правильности, что даёт более устойчивые знания. Разница,如同 авторы объясняют в секции 2, в том, что BCQ создаёт контрастный сигнал, а не regression target.
Подходит ли ZOPP только для VLM (vision-language models)?
В статье эксперименты на Qwen3.5 VLM, но метод не привязан к модальности. Принцип BCQ/NCQ применим к любым задачам, где можно сформулировать «правильный ответ + неправильный вариант». Для text-only моделей NCQ может использовать self-generated wrong answers, для multimodalных — визуальные ошибки.
Как ZOPP сочетается с RLHF и safety alignment?
Никак — и это важно. ZOPP оптимизирует только correctness reward (правильность ответа). Safety, fairness, harm reduction — это отдельные каналы, которые ZOPP не затрагивает. Авторы explicitly предупреждают: перед deploy ZOPP-моделей нужно добавить upstream safety alignment stage и downstream content moderation.
Сколько стоит ZOPP-посттренинг по сравнению с полным RL-посттренингом?
Вычислительно ZOPP сопоставим с GRPO на том же ученике — потому что градиент считается на rollout ученика, как в обычном GRPO. Дополнительные затраты: генерация учительских ответов для BCQ-пар (один forward pass 27B модели на вопрос), что составляет ~15% общего бюджета при batch size 64. Для больших учеников (4B, 9B) накладные расходы на учителя ещё меньше относительно общего бюджета.
Итог
ZOPP — элегантный и практичный метод, который решает конкретную проблему: как заставить маленькую модель учиться у большой без катастрофического дрифта. Перенос учителя из градиента в промпт — идея, которая выглядит очевидной задним числом, но до ZOPP никто не довёл её до работающего рецепта с измеримыми результатами.
Для инженеров, работающих с Edge-моделями и mobile AI, это один из самых практичных результатов сезона. Дата-центровые достижения наконец-то могут спуститься на уровень устройства в кармане. Вопрос только в том, кто первый сделает ZOPP-посттренинг для своих edge-моделей — и получит reasoning на 0.8B, сопоставимый с 9B.