LLM не выполняют инструкции: точность падает с 61% до 20%
Вы пишете модели: «Сделай A, потом B, потом C…» — и на пятнадцатом шаге она сбивается. Не потому что плохо считает, а потому что перестаёт следовать процедуре. Исследователи из IIT Gandhinagar проверили 14 языковых моделей на простейшей задаче — выполнить арифметический алгоритм шаг за шагом — и выяснили, что средняя точность падает с 61% на пяти шагах до 20% на девяноста пяти. Ни размер модели, ни подход к обучению не спасает.
Что такое процедурное выполнение в LLM
Процедурное выполнение (procedural execution) — это способность модели взять явно заданный алгоритм и выполнить его именно так, как написано, шаг за шагом, без пропусков и искажений. Это не рассуждение в привычном смысле — скорее это роль «детерминистического исполнителя», которому дали инструкцию и два числа, а он должен вернуть результат.
Звучит тривиально. Любой калькулятор справится. Но именно здесь LLM удивляют — не в хорошем смысле. Исследование «When LLMs Stop Following Steps» (Panda et al., май 2026) показало: модели регулярно пропускают шаги, теряют промежуточные переменные и останавливаются раньше времени, хотя каждый отдельный шаг — это просто сложение, вычитание, умножение или деление.
Как устроен эксперимент
Команда создала контролируемый бенчмарк: модели получали пошаговый арифметический алгоритм и два числа на входе. Алгоритм инициализировал две переменные — S₁ и S₂ — а затем определял последовательность промежуточных значений через базовые операции из набора {+, −, ×, ÷}. Сложность варьировалась по двум осям: количество шагов (от 5 до 95) и глубина look-back зависимостей — когда текущий шаг ссылается не на ближайший предыдущий результат, а на переменные из нескольких шагов назад.
Всего получилось 55 наборов данных и 55 000 примеров. Для каждой комбинации входных данных исследователи генерировали по 100 примеров, варьируя диапазон чисел ([0,1], [1,10], [10,100]), тип данных (целые и с плавающей точкой) и тип операции (отдельно сложение, вычитание, умножение, деление и mixed-режим). Каждый пример — детерминистически вычислимая задача с однозначно правильным ответом, округлённым до трёх знаков после запятой. Никакой неоднозначности, никаких «а может, модель имела в виду другое».
Моделей тестировали 14: от компактных DeepSeek-R1-Distill-Qwen-1.5B до фронтальных систем вроде GPT-OSS-120B. В списке также Qwen3-4B-Thinking, Mistral-7B-Instruct, Nemotron-30B, Magistral-Small и другие. Охват — разные архитектуры, разные размеры, reasoning-oriented и стандартные модели. Все работали при температуре 0, top-p = 1.0 и максимальной длине генерации 32 768 токенов. Модели должны были обернуть ответ в теги <answer>, чтобы можно было автоматически извлечь и проверить результат.
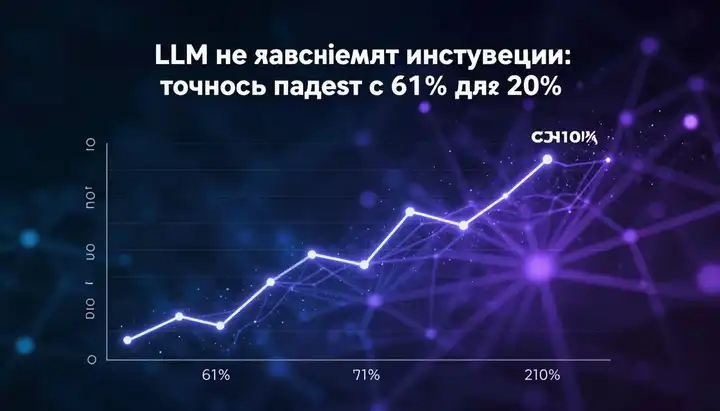
Главный результат: точность обрушивается
Цифры говорят сами за себя. Средняя точность первого ответа (first-answer accuracy) по всем моделям:
5 шагов — 61%. 25 шагов — 38%. 55 шагов — 27%. 95 шагов — 20%.
Это не какая-то одна слабая модель тянет вниз — каждая из 14 моделей показывает монотонное падение. Больше шагов — хуже результат. Причём исследователи проверили, не объясняется ли падение просто ростом величины ожидаемого ответа (мол, числа становятся слишком большими). Оказалось — нет. Медианный ожидаемый результат не растёт систематически с числом шагов, а связь между величиной ответа и ошибкой непоследовательна. Длинные процедуры создают процедурную нагрузку, с которой модели не справляются, независимо от арифметической сложности.
Look-back зависимости усиливают эффект. Когда текущий шаг ссылается на переменную семишаговой давности (look-back 7), средняя точность падает ещё на 18,43 процентных пункта. Моделям приходится «помнить» промежуточные результаты и извлекать их в нужный момент — именно здесь автогрегрессионная архитектура пасует. Контекст размывается, и модель перестаёт различать, какой именно промежуточный результат ей нужен.
Почему модели ломаются — три уровня проблем
Авторы не просто зафиксировали падение точности — они провели детальную диагностику того, как именно модели ошибаются. Выделились три устойчивых паттерна.
Недовыполение — главная проблема. При анализе сгенерированных ответов исследователи классифицировали каждое выполнение как точное (exact), неполное (under) или избыточное (over). С ростом числа шагов доля точных выполнений неуклонно падает, а доля неполных — растёт. Модели просто останавливаются раньше, чем выполнили все шаги. Они не «додумывают» алгоритм до конца. Это ключевой вывод: проблема не в арифметических ошибках — проблема в том, что модель перестаёт вести процедуру.
Потеря ответа. Многие модели, особенно компактные, просто не выдают валидный ответ. DeepSeek-R1-Distill-Qwen-1.5B, Sarvam-30B, Nemotron-30B часто повторяют промпт, генерируют бессвязный текст или забывают обернуть ответ в требуемый тег <answer>. Чем длиннее алгоритм, тем чаще модель «теряется» и не может сформулировать финальный результат. Сильные модели держат non-null answer rate на высоком уровне, но даже у них точность ответов падает — то есть проблема глубже, чем просто «забыла тег».
Ранний ответ вместо выполнения. Некоторые модели — Qwen3-4B-Thinking, Mistral-7B-Instruct, GPT-OSS — выдают ответ в начале генерации, до того как пройдут все шаги. Это похоже на угадывание вместо исполнения: модель пытается «предсказать» результат, а не вычислить его пошагово. Парадоксальным образом reasoning-модели с длинными цепочками рассуждений иногда показывают худшие результаты, потому что генерируют длинные рассуждения, которые уводят их от точного выполнения алгоритма. Модель «думает» вместо того, чтобы «делать».
Размер модели не спасает
Можно было бы предположить, что более крупные модели справляются значительно лучше. В среднем — да, но разрыв не так велик, как ожидается. Компактная Qwen3-4B-Thinking иногда обходит модели в десять раз крупнее на определённых задачах. Nemotron-30B и DeepSeek-R1-Distill-Qwen-14B показывают сопоставимые результаты, хотя отличаются по размеру в несколько раз.
Что действительно коррелирует с провалом — так это тип операции. Сложение и вычитание модели выполняют заметно лучше, чем умножение и деление. При умножении и делении разрыв между правильными и неправильными ответами в терминах медианного ожидаемого результата существенно больше — модели «уезжают» по величине. В mixed-операциях, где тип меняется от шага к шагу, точность падает ещё сильнее: модели путаются не только в числах, но и в том, какую операцию нужно применить на текущем шаге.
Интересно, что чувствительность к входному диапазону — модель-зависимая, а не универсальная. Некоторые маленькие модели (та же Qwen3-4B-Thinking) лучше работают на диапазоне [1,10], чем на [0,1] или [10,100], тогда как для других моделей картина обратная. Единой закономерности нет — каждая архитектура реагирует на масштаб чисел по-своему.
При чём здесь практические задачи
Кто-то скажет: «Ну и что, это же арифметика, в реальных задачах модели используют инструменты». И будет по-своему прав — но лишь отчасти. Исследование моделирует ситуацию, которая возникает повсюду: пользователь даёт модели пошаговую инструкцию и ждёт точного выполнения.
Расчёт налогов по формуле из двадцати полей. Проверка данных по чеклисту из тридцати пунктов. Выполнение бизнес-процесса, где каждый шаг зависит от результата предыдущего. Агентские workflows, где LLM-агент должен пройти по заданному плану из пятидесяти этапов. Выполнение SQL-запросов по многошаговой процедуре трансформации данных. Во всех этих случаях модель получает явный алгоритм и должна его выполнить — а исследование показывает, что именно это она делает всё хуже с каждым дополнительным шагом.
Это объясняет, почему LLM-агенты так часто «зависают» или пропускают шаги в сложных workflows. Не потому что модель «глупая» — а потому что механизм процедурного выполнения у языковых моделей фундаментально хрупок. Автогрегрессионная архитектура предсказывает следующий токен, а не ведёт внутренний счётчик «какой шаг я сейчас выполняю и какие переменные у меня есть».
Что с этим делать на практике
Авторы исследования предлагают понятный путь: использовать tool-augmented agents — то есть давать модели не выполнять вычисления самой, а вызывать внешние инструменты. Если модели трудно поддерживать состояние из 30 шагов, поручите это программе, а модель пусть отвечает за планирование и вызов инструментов.
На практике это разворачивается в несколько конкретных подходов. Разбивайте длинные процедуры на короткие блоки по 5–7 шагов и проверяйте результат каждого — так вы хотя бы будете знать, на каком этапе модель сбилась. Используйте внешние исполнители для детерминистических задач: Python-скрипт не «потеряет» промежуточную переменную на двадцатом шаге, потому что у него есть настоящая память, а не контекстное окно. Добавляйте контрольные точки в промпт — просите модель выводить промежуточные значения после каждых нескольких шагов, чтобы можно было отловить ошибку раньше.
Для агентских систем — разделяйте планирование и выполнение. Пусть модель составляет план (с этим она справляется), а выполняет каждый шаг через вызов инструмента с валидацией результата. Это увеличивает количество запросов к API, но радикально снижает вероятность процедурных ошибок.
И главное: не доверяйте LLM задачи с длинными пошаговыми процедурами без верификации. Если у вас процесс из 50 шагов с зависимостями между ними — языковая модель с вероятностью 80% ошибётся. Это не предположение, это результат систематического тестирования на 55 000 примеров.
Часто задаваемые вопросы
Почему модели не могут выполнить простой алгоритм?
Потому что LLM — это не исполнитель алгоритмов. Это автогрегрессионные модели, которые предсказывают следующий токен на основе контекста. С ростом длины процедуры контекст «размывается», модель теряет промежуточные переменные и начинает угадывать вместо вычисления. Это архитектурное ограничение transformer-архитектуры, а не проблема конкретной модели.
Reasoning-модели (o1, DeepSeek-R1) справляются лучше?
В среднем reasoning-модели действительно показывают лучшие результаты, но парадокс в том, что длинные цепочки рассуждений иногда ухудшают выполнение. Модель начинает «думать» вместо того, чтобы чётко следовать инструкции. На коротких алгоритмах из 5–15 шагов reasoning помогает, на длинных процедурах — может мешать, уводя модель от точного исполнения.
Поможет ли увеличение контекстного окна?
Частично. Большее контекстное окно позволяет модели «видеть» больше шагов, но исследование показывает, что проблема не только в забывании начала. Модель перестаёт выполнять процедуру — останавливается раньше времени или переключается на угадывание. Больший контекст смягчает проблему, но не решает её полностью.
Итог
Исследование «When LLMs Stop Following Steps» — один из тех редких случаев, когда контролируемый эксперимент ставит жирную точку в дискуссии. Языковые модели не просто «иногда ошибаются в вычислениях» — они систематически теряют способность выполнять пошаговые инструкции при увеличении длины процедуры. Точность обрушивается с 61% до 20%, и ни размер модели, ни reasoning-обучение не решают проблему полностью.
Практический вывод однозначен: для задач, где важна точность многошагового выполнения, используйте инструменты и верификацию. А LLM оставьте то, с чем она действительно справляется — генерацию текста, рассуждение на высоком уровне и коммуникацию. Калькулятор всё равно считает лучше — и это не комплимент калькулятору, а факт, подтверждённый 55 000 экспериментов.